深入理解现代浏览器
TODO: 重新翻译原英文文章,然后整理成自己的内容
本文转载自 360 W3C 工作组 。之所以专门转载该文章,是因为该文章很不错,但是几乎所有链接的格式都是有问题的。而且还缺失了某些图片。此外,原文章本身就是翻译转载,但转载时某些内容其实被更改了。所以我会参考英文原文,将某些知识点重新描述成我喜欢的样子。最后,图片的注释信息来自英文原文。
各位,如果你的职业是开挖掘机,你说要不要深入理解挖掘机?通常来说,深入理解你操纵的机器才能最终达到人机一体的境界。
当然,你可以说:不用,因为如果挖掘机不好使,我可以换一台。嗯,也有道理。不过,假如你同时又是一名前端开发者,那你要不要深入理解浏览器呢?注意,身为前端,你不太可能有机会因为浏览器不好使就强迫用户换一个你认为好使的。这时候,你好像别无选择了。
不过也不用害怕,今天我们的现代浏览器深度游会非常轻松、快乐。这首先必须感谢一位名叫 Mariko Kosaka 小坂真子 的同行。她在 Scripto 工作,2018年9月在 Google 开发者网站上发表了 “Inside look at modern web browser” 系列文章。本文就是她那 4 篇文章的“集合版”。为什么搞这个“集合版”?因为她的 4 篇文章写得实在太好,更难得的是人家亲手绘制了一大堆生动的配图和动画,这让深入理解现代浏览器变得更加轻松愉快。
好了,言归正传。本文分 4 个部分,对应上述 4 篇文章(原文链接附后)。
- 架构:以 Chrome 为例,介绍现代浏览器的实现架构。1
- 导航:从输入 URL 到获到 HTML 响应称为导航。2
- 渲染:浏览器解析 HTML、下载外部资源、计算样式并把网页绘制到屏幕上。3
- 交互:用户输入事件的处理与优化。4
先来个小小的序言。很多人在开发网站时,只关注怎么写自己的代码,关注怎么提升自己的开发效率。这些当然重要,但是写到一定的阶段,就应该停下来想想:浏览器到底会怎么运行你写的代码。如果你能多了解一些浏览器,然后对它好一点,那么就会更容易达成你提升用户体验的目标。
架构
计算机的核心是 CPU 和 GPU
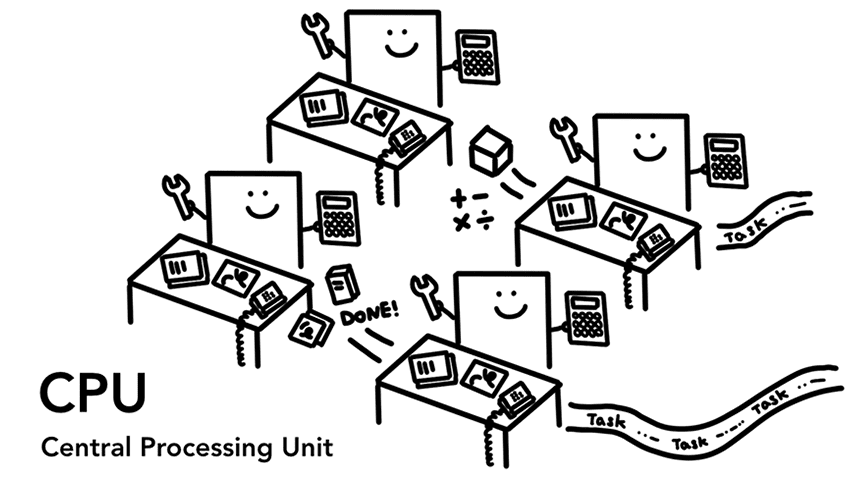 Figure 1: 4 CPU cores as office workers sitting at each desk handling tasks as they come in(4 个 CPU 核心作为办公室员工,坐在办公桌前处理任务)
Figure 1: 4 CPU cores as office workers sitting at each desk handling tasks as they come in(4 个 CPU 核心作为办公室员工,坐在办公桌前处理任务)
CPU(Central Processing Unit, 中央处理器),它相当于计算机的大脑,少而精,可以处理各种复杂的任务。
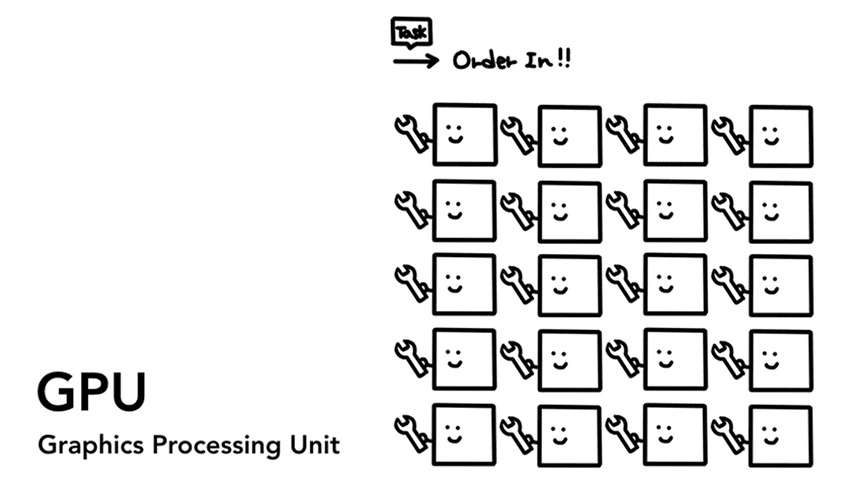 Figure 2: Many GPU cores with wrench suggesting they handle a limited task(许多拿着扳手的 GPU 核心,建议只给他们处理简单的任务)
Figure 2: Many GPU cores with wrench suggesting they handle a limited task(许多拿着扳手的 GPU 核心,建议只给他们处理简单的任务)
GPU(Graphics Processing Unit, 图形处理器),与 CPU 不同,GPU 的优势在于多!但它只能处理(相对 CPU 而言)简单的任务。
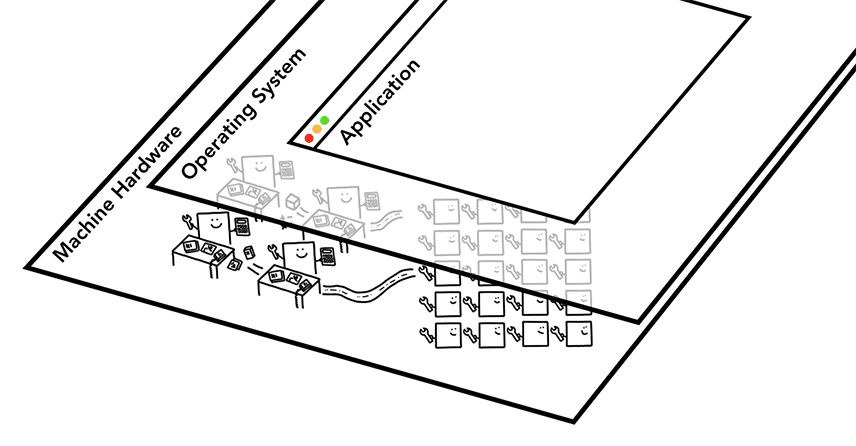 Figure 3: Three layers of computer architecture. Machine Hardware at the bottom, Operating System in the middle, and Application on top.(三层计算机体系结构。底部是硬件,中间是操作系统,顶部是应用程序)
Figure 3: Three layers of computer architecture. Machine Hardware at the bottom, Operating System in the middle, and Application on top.(三层计算机体系结构。底部是硬件,中间是操作系统,顶部是应用程序)
进程和线程
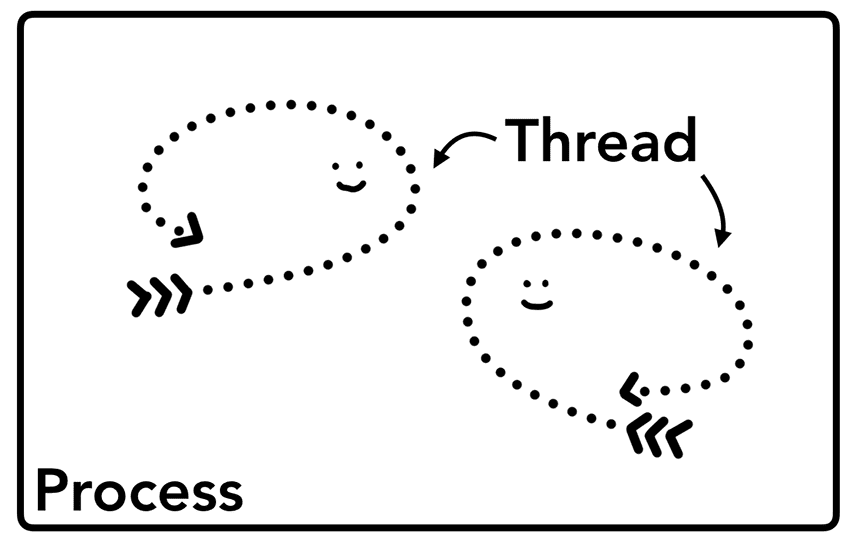 Figure 4: Process as a bounding box, threads as abstract fish swimming inside of a process(进程是一个盒子,线程在盒子里面可以像鱼一样自由移动)
Figure 4: Process as a bounding box, threads as abstract fish swimming inside of a process(进程是一个盒子,线程在盒子里面可以像鱼一样自由移动)
启动应用时,系统会创建一个进程。程序可能会创建线程来帮助其完成工作,但这不是必需的。操作系统会为进程提供内存块 (slab),所有应用状态都保存在这个私有内存空间中。当您关闭该应用时,进程也会消失,操作系统也会释放对应的内存。
 Figure 5: Diagram of a process using memory space and storing application data(进程使用内存空间和存储应用程序数据的示意图)
Figure 5: Diagram of a process using memory space and storing application data(进程使用内存空间和存储应用程序数据的示意图)
一个进程可以请求操作系统启动另一个进程来运行不同的任务。在这种情况下,系统会将内存的不同部分分配给新进程。如果两个进程需要通信,它们可以使用 IPC(Inter Process Communication, 进程间通信) 进行通信。这是许多应用的运作方式。这样一来,如果应用中的某个进程无响应,可以只重启该进程,而无需重启整个应用(多个进程)。
 Figure 6: Diagram of separate processes communicating over IPC(不同进程之间通过 IPC 通信)
Figure 6: Diagram of separate processes communicating over IPC(不同进程之间通过 IPC 通信)
浏览器架构
Web 浏览器的架构,可以实现为一个进程包含多个线程,也可以实现为很多进程包含少数线程通过 IPC 通信。
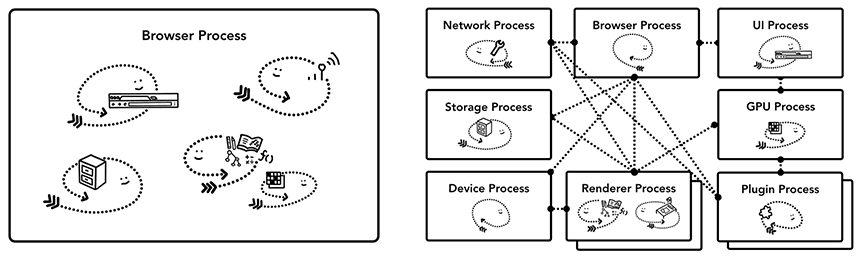 Figure 7: Different browser architectures in process / thread diagram(不同浏览器架构的进程/线程示意图)
Figure 7: Different browser architectures in process / thread diagram(不同浏览器架构的进程/线程示意图)
如何实现浏览器,并没有统一的标准。本文使用的 Chrome 架构是这样的:最上层是浏览器进程,负责协调承担各项工作的其他进程,比如实用程序进程、渲染器进程、GPU 进程、插件进程等,如下图所示。
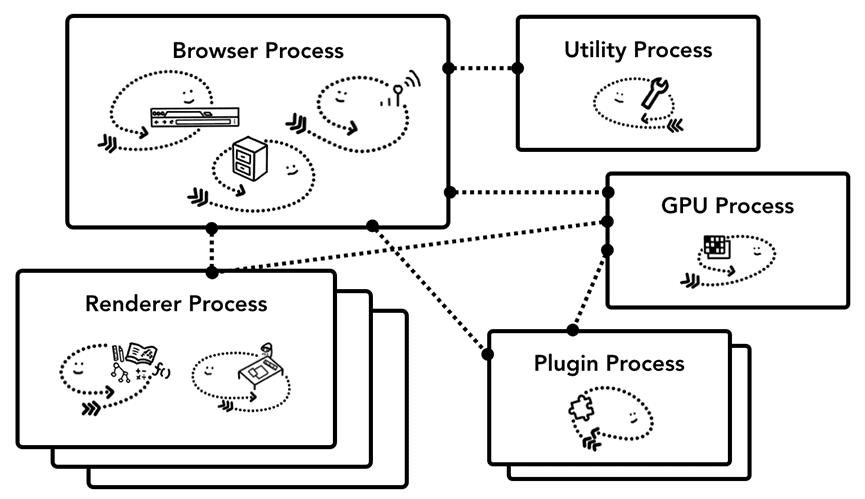 Figure 8: Diagram of Chrome’s multi-process architecture. Multiple layers are shown under Renderer Process to represent Chrome running multiple Renderer Processes for each tab.(chrome 多进程架构示意图。图中 Renderer Process 下有多个图层,表示 Chrome 中每个标签页会运行多个渲染器进程)
Figure 8: Diagram of Chrome’s multi-process architecture. Multiple layers are shown under Renderer Process to represent Chrome running multiple Renderer Processes for each tab.(chrome 多进程架构示意图。图中 Renderer Process 下有多个图层,表示 Chrome 中每个标签页会运行多个渲染器进程)
渲染器进程对应新开的标签页,每新开一个标签页,就会创建一个新的渲染器进程。不仅如此,Chrome 还会尽量给每个站点新开一个渲染器进程,包括 iframe 中的站点,以实现站点隔离。
下面详细了解一下每个进程的作用,可以参考下图。
- 浏览器进程 (Browser):控制浏览器这个应用的 chrome(主框架)部分,包括地址栏、书签、前进/后退按钮等,同时也会处理浏览器不可见的高权限任务,如发送网络请求、访问文件。
- 渲染器进程 (Renderer):负责在标签页中显示网站及处理事件。
- 插件进程 (Plugin):控制网站用到的所有插件。
- GPU 进程:在独立的进程中处理 GPU 任务。之所以放到独立的进程,是因为 GPU 要处理来自多个应用的请求,但要在同一个界面上绘制图形。
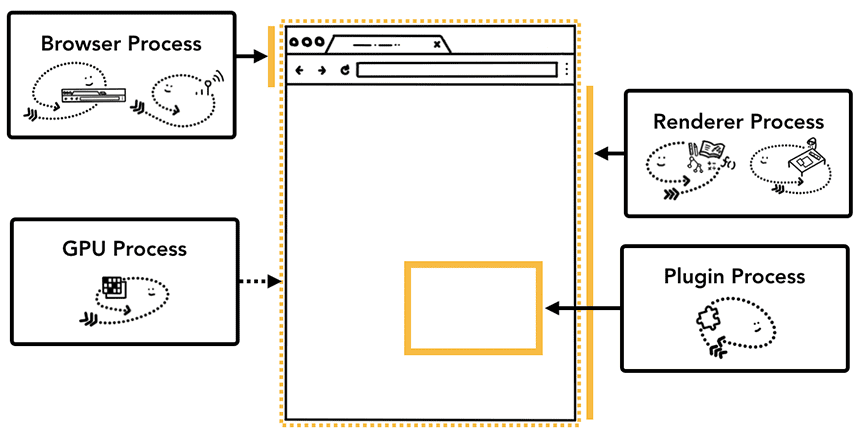 Figure 9: Different processes pointing to different parts of browser UI(不同的进程指向浏览器 UI 的不同部分)
Figure 9: Different processes pointing to different parts of browser UI(不同的进程指向浏览器 UI 的不同部分)
当然,还有其他进程,比如扩展进程、实用程序进程。要知道你的 Chrome 当前打开了多少个进程,点击右上角的按钮,选择“更多工具”,再选择“任务管理器”。
Chrome 的多进程架构的优点
最简单的情况下,可以想像一个标签页就是一个渲染器进程,比如 3 个标签页就是 3 个渲染器进程。这时候,如果有一个渲染器崩溃了,只要把它关掉即可,不会影响其他标签页。如果所有标签页都运行在一个进程中,那只要有一个标签页卡住,所有标签页都会卡住。
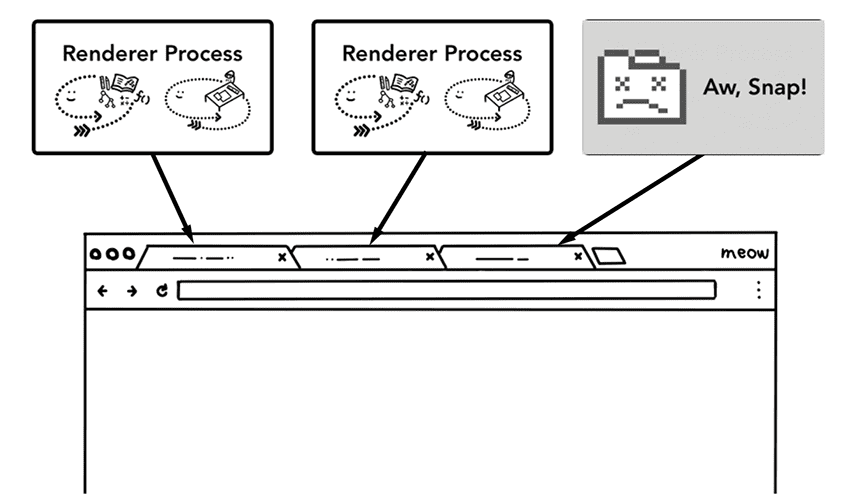 Figure 10: Diagram showing multiple processes running each tab(图片显示了每个标签页中各自拥有多个进程)
Figure 10: Diagram showing multiple processes running each tab(图片显示了每个标签页中各自拥有多个进程)
除此之外,多进程架构还有助于安全和隔离。因为操作系统有限制进程特权的机制,浏览器可以借此限制某些进程的能力。比如,Chrome 会限制处理任意用户输入的渲染器进程,不让它任意访问文件。
由于进程都有自己私有的内存空间,因此每个进程可能都会保存某个公共基础设施(比如 Chrome 的 JavaScript 引擎 V8)的多个副本。这会导致内存占用增多。为节省内存,Chrome 会限制自己可以打开的进程数量。限制的条件取决于设备内存和 CPU 配置。达到限制条件后,Chrome 会用一个进程处理同一个站点的多个标签页。
Chrome 架构进化的目标是将整个浏览器程序的不同部分服务化,便于分割或合并。基本思路是在高配设备中,每个服务独立开进程,保证稳定;在低配设备中,多个服务合并为一个进程,节约资源。同样的思路也应用到了 Android 上。
 Figure 11: Diagram of Chrome’s servicification moving different services into multiple processes and a single browser process(Chrome 将不同服务移入多个进程和一个浏览器进程的示意图)
Figure 11: Diagram of Chrome’s servicification moving different services into multiple processes and a single browser process(Chrome 将不同服务移入多个进程和一个浏览器进程的示意图)
重点说一说站点隔离。站点隔离是新近引入 Chrome 的一个里程碑式特性,即每个跨站点 iframe 都运行一个独立的渲染器进程。即便像前面说的那样,每个标签页单开一个渲染器进程,但允许跨站点的 iframe 运行在同一个渲染器进程中并共享内存空间,那安全攻击仍然有可能绕开同源策略,而且有人发现在现代 CPU 中,进程有可能读取任意内存。
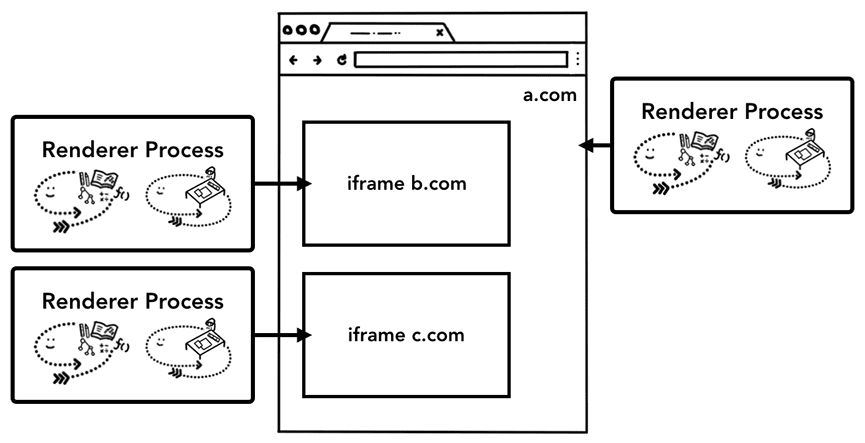 Figure 12: Diagram of site isolation; multiple renderer processes pointing to iframes within a site(站点格式示意图。多个渲染器进程指向一个网站内的多个 iframe)
Figure 12: Diagram of site isolation; multiple renderer processes pointing to iframes within a site(站点格式示意图。多个渲染器进程指向一个网站内的多个 iframe)
进程隔离是隔离站点、确保上网安全最有效的方式。Chrome 67 桌面版默认采用站点隔离。站点隔离是多年工程化努力的结果,它并非多开几个渲染器进程那么简单。比如,不同的 iframe 运行在不同进程中,开发工具在后台仍然要做到无缝切换,而且即便简单地 Ctrl+F 查找也会涉及在不同进程中搜索。
导航
导航涉及浏览器进程与线程间为显示网页而通信。一切从用户在浏览器中输入一个 URL 开始。输入 URL 之后,浏览器会通过互联网获取数据并显示网页。从请求网页到浏览器准备渲染网页的过程,叫做导航。
如前所述,标签页外面的一切都由浏览器进程处理。浏览器进程中有线程(UI 线程)负责绘制浏览器的按钮和地址栏,有线程(网络线程)负责处理网络请求并从互联网接收数据,有线程(存储线程)负责访问文件和存储数据。
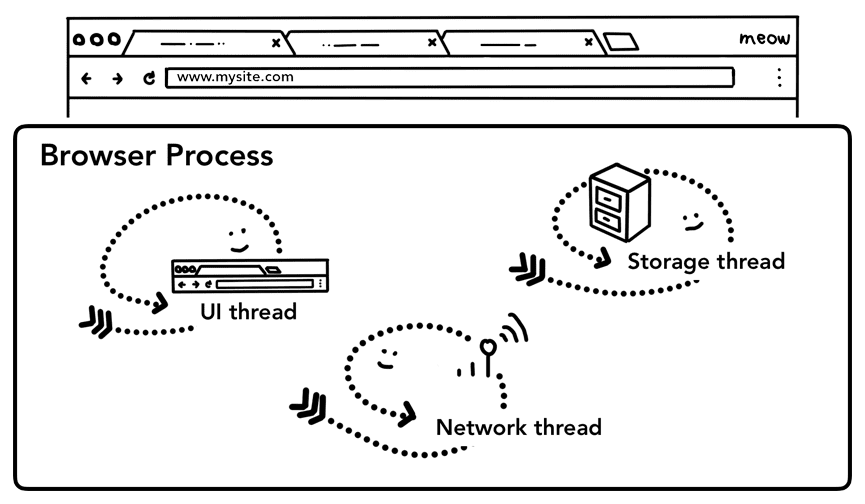 Figure 1: Browser UI at the top, diagram of the browser process with UI, network, and storage thread inside at the bottom(图片的上面部分是浏览器 UI 图,下面部分表示浏览器进程,其中包含 UI 线程、网络线程和存储线程)
Figure 1: Browser UI at the top, diagram of the browser process with UI, network, and storage thread inside at the bottom(图片的上面部分是浏览器 UI 图,下面部分表示浏览器进程,其中包含 UI 线程、网络线程和存储线程)
下面我们逐步看一看导航的几个步骤。
简单导航
第一步:处理输入
UI 线程会判断用户输入的是查询字符串还是 URL。因为 Chrome 的地址栏同时也是搜索框。
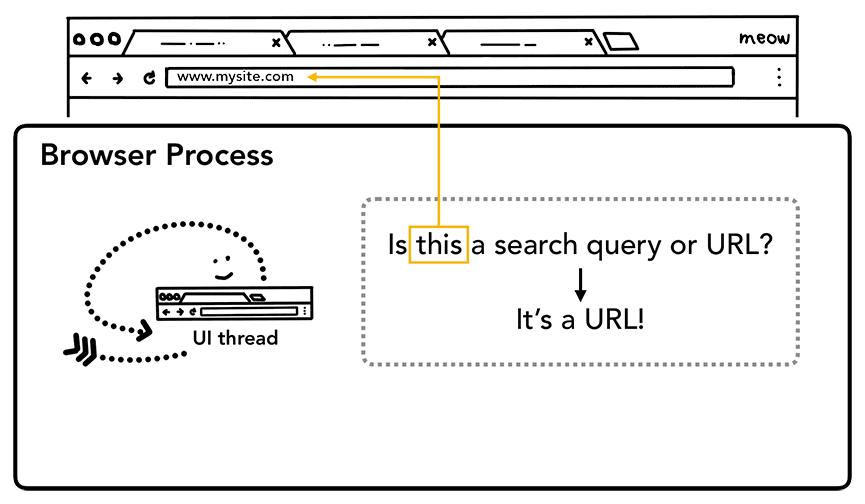 Figure 1: UI Thread asking if the input is a search query or a URL(UI 线程询问输入的内容是链接还是搜索词)
Figure 1: UI Thread asking if the input is a search query or a URL(UI 线程询问输入的内容是链接还是搜索词)
第二步:开始导航
如果输入的是 URL,UI 线程会通知网络线程发起网络调用,获取网站内容。此时标签页左端显示旋转图标,网络线程进行 DNS 查询、建立 TLS 连接(如果是 HTTPS 的话)。网络线程可能收到服务器的重定向头部,如 HTTP 301。此时网络线程会跟 UI 线程沟通,告诉它服务器要求重定向。然后,再发起对另一个 URL 的请求。
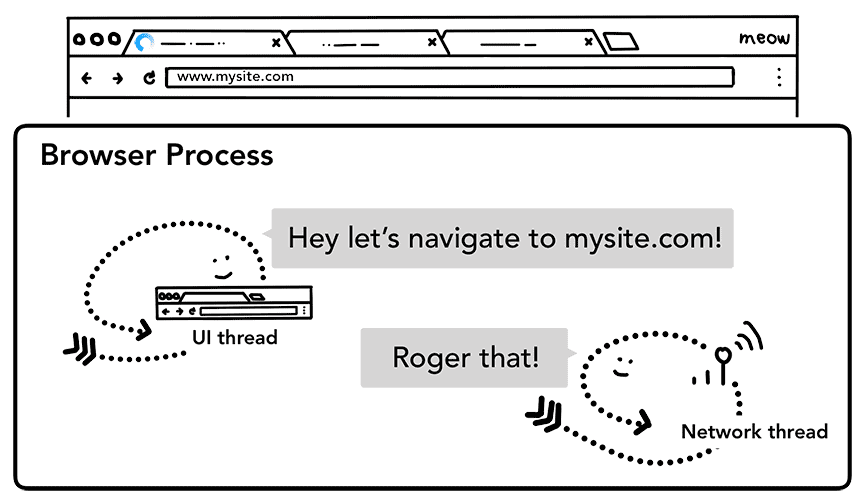 Figure 2: the UI thread talking to the network thread to navigate to mysite.com(UI 线程与网络线程对话以导航到 mysite.com)_
Figure 2: the UI thread talking to the network thread to navigate to mysite.com(UI 线程与网络线程对话以导航到 mysite.com)_
第三步:读取响应
服务器返回的响应体到来之后,网络线程会检查接收到的前几个字节。响应的 Content-Type 头部应该包含数据类型,如果没有这个字段,则需要 MIME 类型嗅探。看看 Chrome 源码中的注释就知道这一块有多难搞。
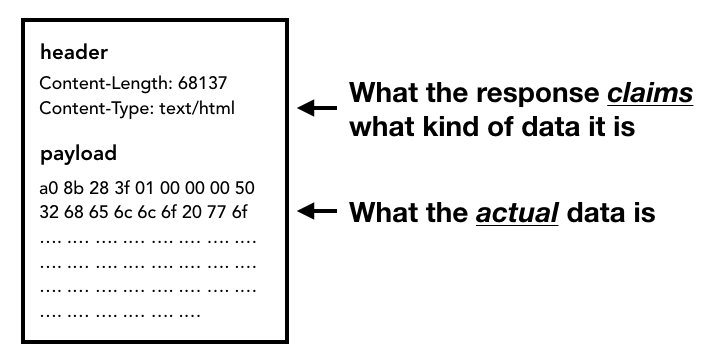 Figure 3: response header which contains Content-Type and payload which is the actual data(包含 Content-Type 的响应头,和包含具体数据的负载)
Figure 3: response header which contains Content-Type and payload which is the actual data(包含 Content-Type 的响应头,和包含具体数据的负载)
如果响应是 HTML 文件,那下一步就是把数据交给渲染器进程。但如果是一个 zip 文件或其他文件,那就意味着是一个下载请求,需要把数据传给下载管理器。
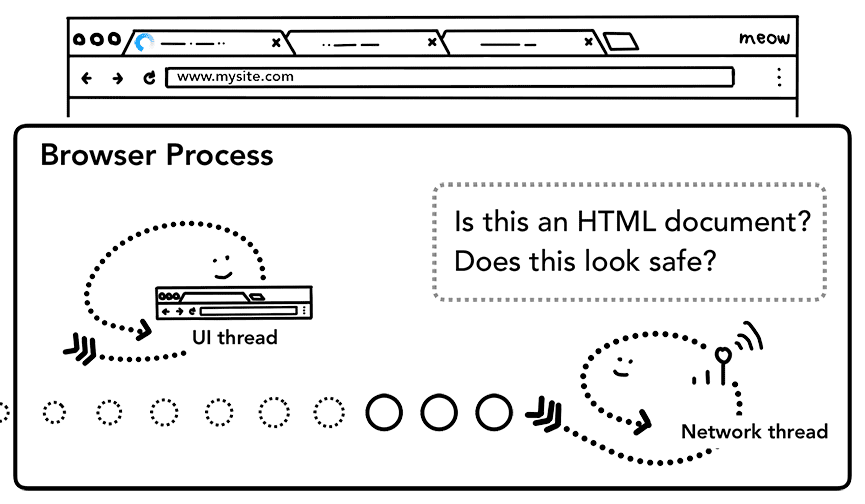 Figure 4: Network thread asking if response data is HTML from a safe site(网络线程询问响应数据是不是 HTML?是否为来自安全网站的?)
Figure 4: Network thread asking if response data is HTML from a safe site(网络线程询问响应数据是不是 HTML?是否为来自安全网站的?)
此时也是“安全浏览”检查的环节。如果域名和响应数据匹配已知的恶意网站,网络线程会显示警告页。此外,CORB (Cross Origin Read Blocking) 检查也会执行,以确保敏感的跨站点数据不会发送给渲染器进程。
第四步:联系渲染器进程
所有查检完毕,网络线程确认浏览器可以导航到用户请求的网站,于是会通知 UI 线程数据已经准备好了。UI 线程会联系渲染器进程渲染网页。
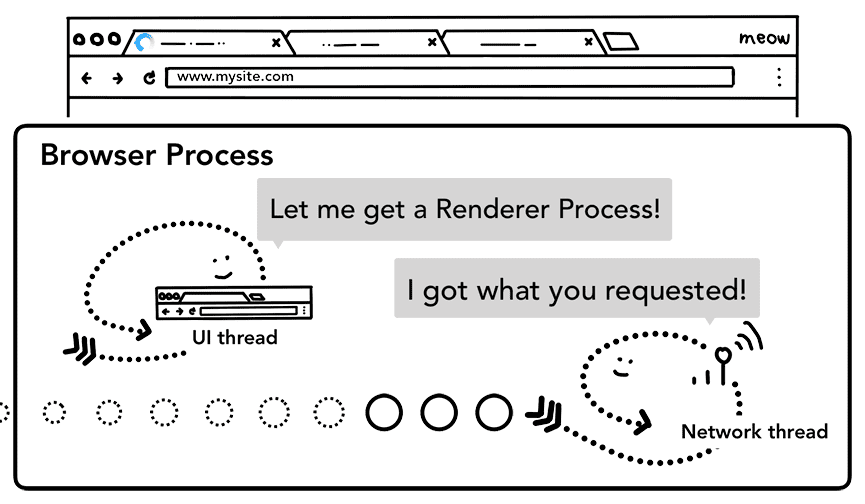 Figure 5: Network thread telling UI thread to find Renderer Process(网络线程让 UI 线程去获取渲染器进程)
Figure 5: Network thread telling UI thread to find Renderer Process(网络线程让 UI 线程去获取渲染器进程)
由于网络请求可能要花几百毫秒才能拿到响应,这里还会应用一个优化策略。第二步 UI 线程要求网络线程发送请求后,已经知道可能要导航到哪个网站去了。因此在发送网络请求的同时,UI 线程会提前联系或并行启动一个渲染器进程。这样在网络线程收到数据后,就已经有渲染器进程原地待命了。如果发生了重定向,这个待命进程可能用不上,而是换作其他进程去处理。
第五步:提交导航
数据和渲染器进程都有了,就可以通过 IPC 从浏览器进程向渲染器进程提交导航。渲染器进程也会同时接收到不间断的 HTML 数据流。当浏览器进程收到渲染器进程的确认消息后,导航完成,文档加载阶段开始。
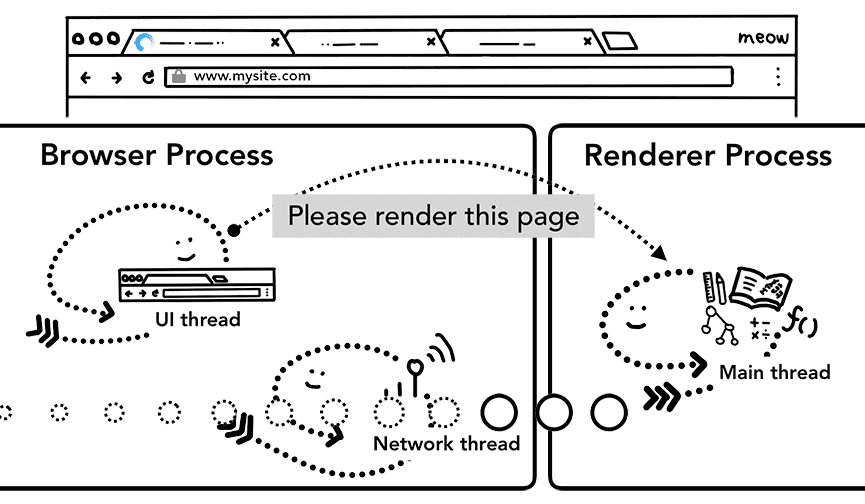 Figure 6: IPC between the browser and the renderer processes, requesting to render the page(浏览器进程和渲染器进程之间通过 IPC 通信,来渲染一个页面)
Figure 6: IPC between the browser and the renderer processes, requesting to render the page(浏览器进程和渲染器进程之间通过 IPC 通信,来渲染一个页面)
此时,地址栏会更新,安全指示图标和网站设置 UI 也会反映新页面的信息。当前标签页面的会话历史会更新,后退/前进按钮起作用。为便于标签页/会话在关闭标签页或窗口后恢复,会话历史会写入磁盘。
最后一步:初始加载完成
提交导航之后,渲染器进程将负责加载资源和渲染页面(具体细节后面介绍)。而在“完成”渲染后(在所有 iframe 中的 onload 事件触发且执行完成后),渲染器进程会通过 IPC 给浏览器进程发送一个消息。此时,UI 线程停止标签页上的旋转图标。
初始加载完成后,客户端 JavaScript 仍然可能加载额外资源并重新渲染页面。
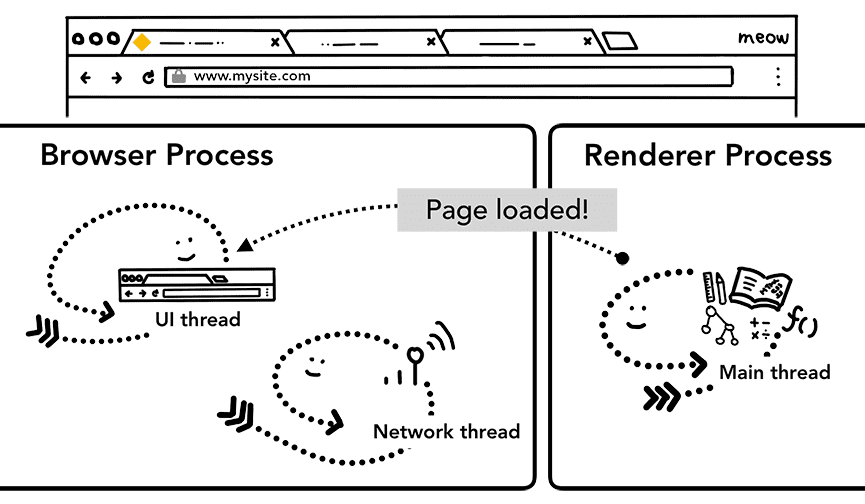 Figure 7: IPC from the renderer to the browser process to notify the page has “loaded”(渲染器进程通过 IPC 让浏览器进程去通知页面已经 loaded )
Figure 7: IPC from the renderer to the browser process to notify the page has “loaded”(渲染器进程通过 IPC 让浏览器进程去通知页面已经 loaded )
在一个网站中导航到其他网站
如果此时用户在地址又输入了其他 URL 呢?浏览器进程还会重复上述步骤,导航到新站点。不过在此之前,需要确认已渲染的网站是否关注 beforeunload 事件。因为标签页中的一切,包括 JavaScript 代码都由渲染器进程处理,所以浏览器进程必须与当前的渲染器进程确认后再导航到新站点。
如果导航请求来自当前渲染器进程(用户点击了链接或 JavaScript 运行了 window.location = "https://newsite.com"),渲染器进程首先会检查 beforeunload 处理程序。然后,它会走一遍与浏览器进程触发导航同样的过程。唯一的区别在于导航请求是由渲染器进程提交给浏览器进程的。
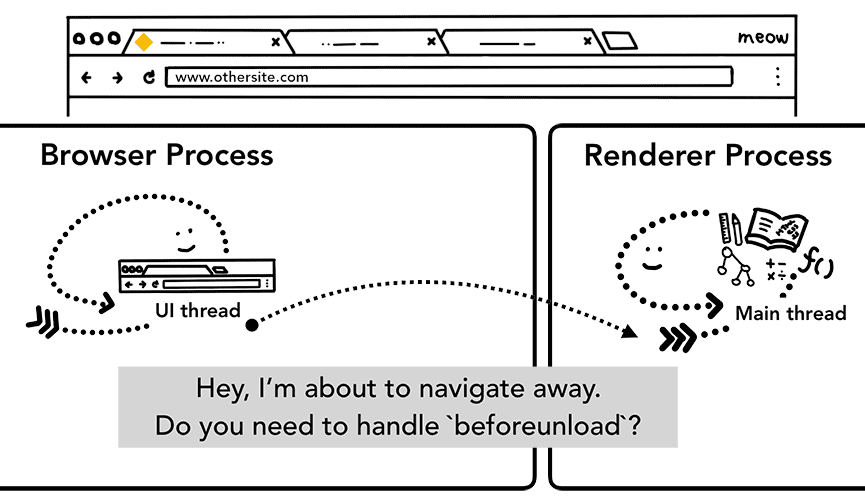 Figure 8: IPC from the browser process to a renderer process telling it that it’s about to navigate to a different site(浏览器进程告知渲染器进程即将导航到另外的一个网站)
Figure 8: IPC from the browser process to a renderer process telling it that it’s about to navigate to a different site(浏览器进程告知渲染器进程即将导航到另外的一个网站)
导航到不同的网站时,会有一个新的独立渲染器进程负责处理新导航,而老的渲染器进程要负责处理 unload 之类的事件。更多细节,可以参考“页面生命周期 API”。
注意:不要添加无条件 beforeunload 处理程序。这会增加延迟时间,因为该处理程序会在导航开始之前执行。所以,通常只在需要提醒用户可能会丢失在网页上输入的数据时,才会添加 beforeunload 事件。
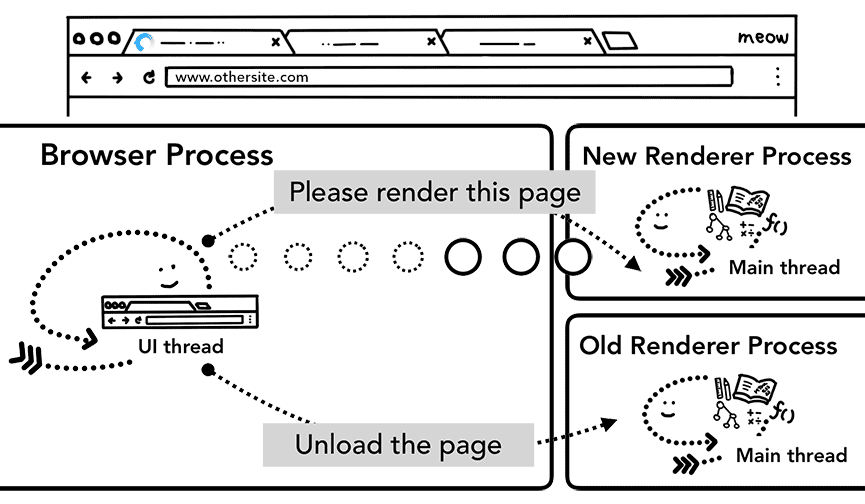 Figure 9: 2 IPCs from a browser process to a new renderer process telling to render the page and telling old renderer process to unload(浏览器进程告知新的渲染器进程渲染一个新页面,同时告知旧的渲染器进程卸载旧页面)
Figure 9: 2 IPCs from a browser process to a new renderer process telling to render the page and telling old renderer process to unload(浏览器进程告知新的渲染器进程渲染一个新页面,同时告知旧的渲染器进程卸载旧页面)
Service Worker
另外,导航阶段还可能涉及 Service Worker,即网页应用中的网络代理服务,开发者可以通过它控制本地缓存的内容,以及何时从网络获取新数据。如果 Service Worker 设置为从缓存加载页面,则无需从网络请求数据。
需要重点注意的是:Service Worker 其实就是运行在渲染器进程中的 JavaScript 代码。那么,导航到一个站点时,浏览器进程如何知道该站点有 Service Worker 呢?答案就是通过网络线程查找 Service Worker 作用域。
 Figure 10: the network thread in the browser process looking up service worker scope(浏览器进程中的网络线程查找 Service Worker 作用域,以判断该站点是否有注册 Service Worker)
Figure 10: the network thread in the browser process looking up service worker scope(浏览器进程中的网络线程查找 Service Worker 作用域,以判断该站点是否有注册 Service Worker)
当一个网站注册 Server Worker 后,Server Worker 作用域将会被记录下来(想要了解更多有关 Server Worker 作用域的内容,可以查看service worker lifecycle)
导航到一个站点时,网络线程会根据已注册的 Service Worker 作用域,判断该站点是否有注册 Service Worker。如果有,那么 UI 线程就会让一个渲染器进程执行对应的 Service Worker 代码。此时,Service Worker 可以选择从网络请求新资源;或者可以选择直接从缓存中加载数据。
听起来似乎和 PWA 优点类似?没错,Service Worker 可以和 PWA(Progressive Web App) 结合起来,实现离线网页。详细内容就不在此展开了。
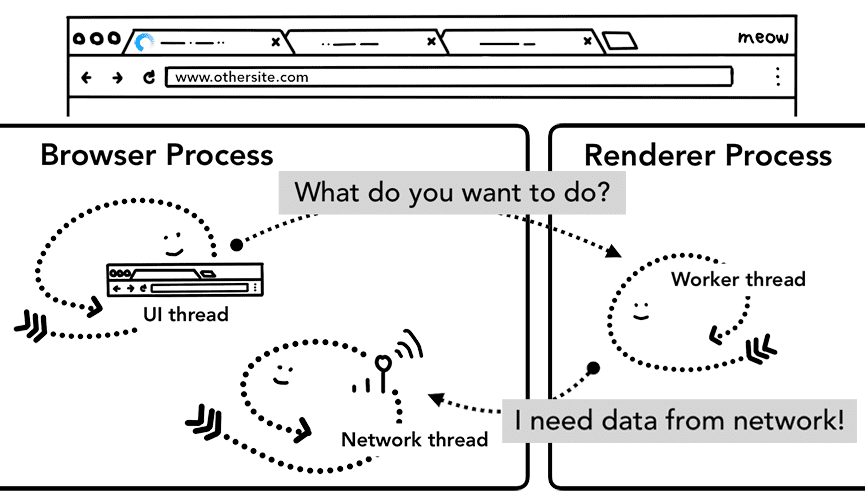 Figure 11: the UI thread in a browser process starting up a renderer process to handle service workers; a worker thread in a renderer process then requests data from the network(浏览器进程中的 UI 线程会启动一个渲染器进程以处理 Service Worker,然后渲染器进程中的工作线程会从网络请求新的数据)
Figure 11: the UI thread in a browser process starting up a renderer process to handle service workers; a worker thread in a renderer process then requests data from the network(浏览器进程中的 UI 线程会启动一个渲染器进程以处理 Service Worker,然后渲染器进程中的工作线程会从网络请求新的数据)
如果 Service Worker 最终决定从网络请求数据,浏览器进程与渲染器进程间的这种往返通信会导致延迟。因此,这里会有一个“导航预加载”的优化,即在 Service Worker 启动的同时预先加载资源,加载请求通过 HTTP 头部与服务器沟通,服务器决定是否完全更新内容。
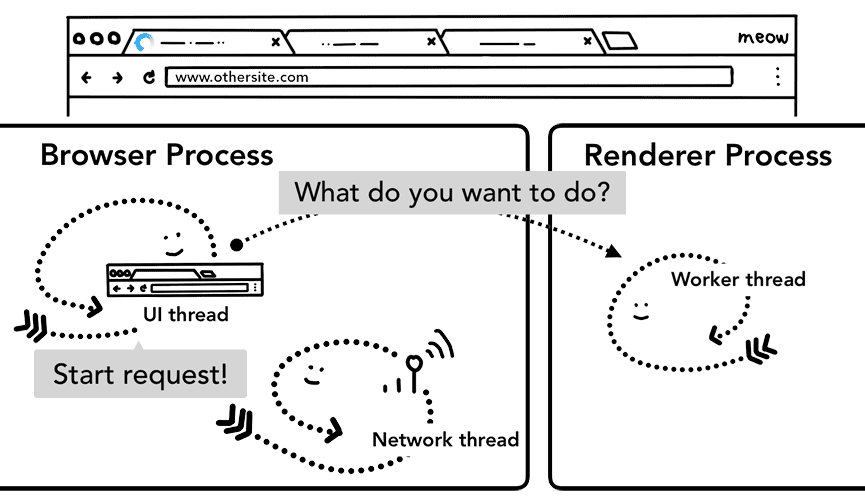 Figure 12: the UI thread in a browser process starting up a renderer process to handle service worker while kicking off network request in parallel(浏览器进程中的 UI 线程在启动渲染器进程来处理 Service Worker 的同时,会并行启动网络请求)
Figure 12: the UI thread in a browser process starting up a renderer process to handle service worker while kicking off network request in parallel(浏览器进程中的 UI 线程在启动渲染器进程来处理 Service Worker 的同时,会并行启动网络请求)
渲染
渲染是渲染器进程内部的工作,涉及 Web 性能的诸多方面(详细内容可以参考为什么速度很重要)。标签页中的一切都由渲染器进程负责处理,其中主线程负责运行大多数客户端 JavaScript 代码,少量代码可能会由工作线程处理(如果用到了 Web Worker 或 Service Worker)。合成器(compositor)线程和栅格化(raster)线程负责高效、平滑地渲染页面。
渲染器进程的核心任务是把 HTML、CSS 和 JavaScript 转换成用户可以交互的网页。接下来,我们从整体上过一遍渲染器进程处理 Web 内容的各个阶段。
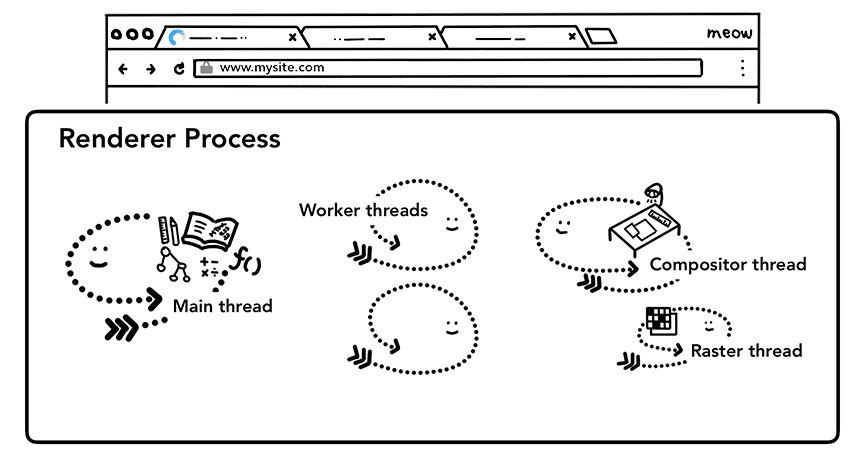 Figure 1: Renderer process with a main thread, worker threads, a compositor thread, and a raster thread inside(渲染器进程内拥有一个主线程、多个工作线程、一个合成器线程和一个栅格化线程)
Figure 1: Renderer process with a main thread, worker threads, a compositor thread, and a raster thread inside(渲染器进程内拥有一个主线程、多个工作线程、一个合成器线程和一个栅格化线程)
解析 HTML
构建 DOM
渲染器进程收到导航的提交消息后,开始接收 HTML,其主线程开始解析文本字符串(HTML),并将它转换为 DOM(Document Object Model,文档对象模型)。
DOM 是浏览器内部对页面的表示,也是 JavaScript 与之交互的数据结构和 API。
如何将 HTML 解析为 DOM 由 HTML 标准定义。HTML 标准要求浏览器兼容错误的 HTML 写法,因此浏览器会“忍气吞声”,绝不报错。详情可以看看“解析器错误处理及怪异情形简介”。
加载子资源
网站都会用到图片、CSS 和 JavaScript 等外部资源。浏览器需要从缓存或网络加载这些文件。主线程可以在解析并构建 DOM 的过程中发现一个加载一个,但这样效率太低。为此,Chrome 会在解析同时并发运行“预加载扫描器”,当发现 HTML 文档中有 <img> 或 <link> 时,预加载扫描器会将请求提交给浏览器进程中的网络线程。
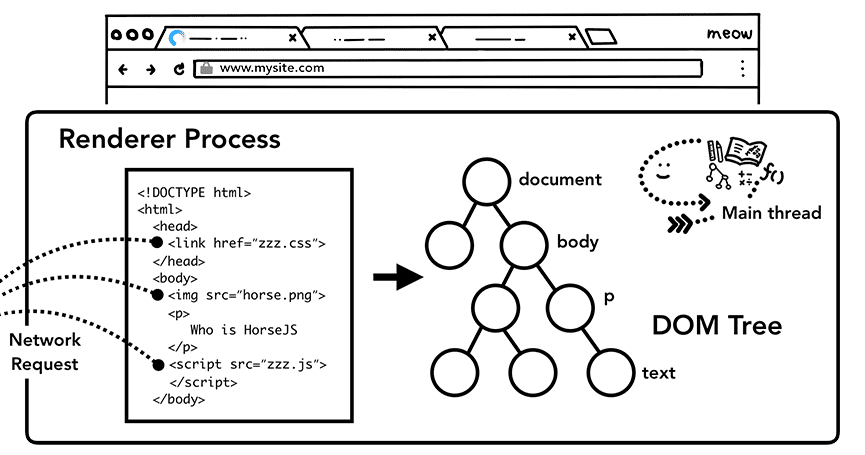 Figure 2: The main thread parsing HTML and building a DOM tree(主线程解析 HTML 并构建 DOM 树)
Figure 2: The main thread parsing HTML and building a DOM tree(主线程解析 HTML 并构建 DOM 树)
JavaScript 可能阻塞解析
如果 HTML 解析器碰到 <script> 标签,会暂停解析 HTML 文档并加载、解析和执行 JavaScript 代码。因为 JavaScript 有可能通过 document.write() 修改文档,进而改变 DOM 结构(HTML 标准的“解析模型”有一张图可以一目了然: Overview of the parsing model)。所以 HTML 解析器必须停下来执行 JavaScript,然后再恢复解析 HTML。至于执行 JavaScript 的细节,大家可以关注V8团队相关的分享。
 Overview of the parsing model
Overview of the parsing model
提示浏览器应如何加载资源
为了更好地加载资源,可以通过很多方式告诉浏览器。如果 JavaScript 没有用到 document.write(),那么可以在 <script> 标签上添加 async 或 defer 属性。这样浏览器就会异步运行 JavaScript 代码,不会阻塞解析。合适的话,可以考虑使用 JavaScript 模块。再比如,<link rel="preload"> 告诉浏览器该资源对于当前导航非常重要,应该尽快下载。关于资源加载优先级,可以参考资源优先级。
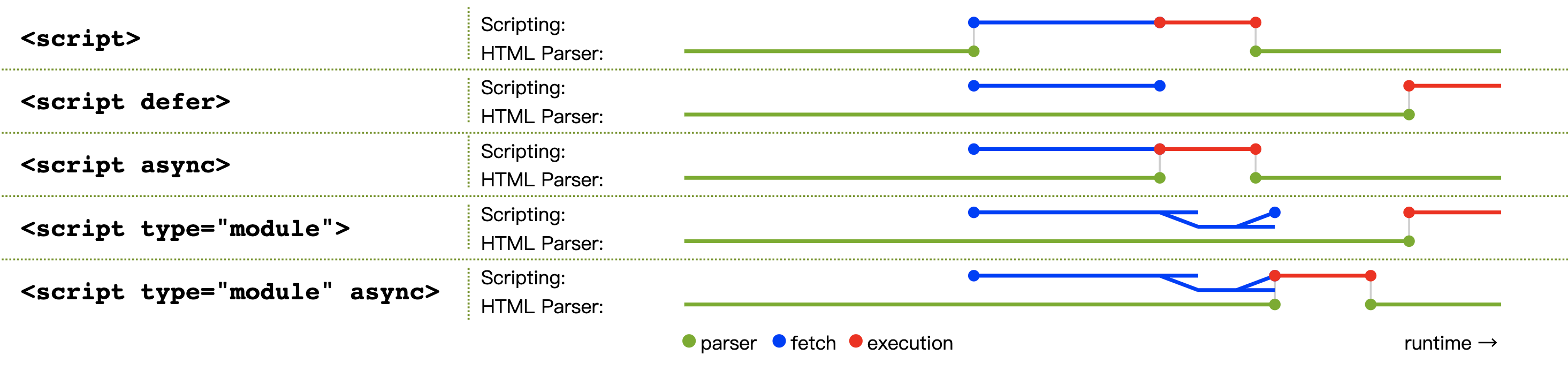 各种 script 脚本加载方式的时间图
各种 script 脚本加载方式的时间图
计算样式
光有 DOM 还不行,因为并不知道页面应该长啥样。所以接下来,主线程要解析 CSS 并计算每个 DOM 节点的样式。这个过程就是根据 CSS 选择符,确定每个元素要应用什么样式。在 Chrome 开发工具“计算的样式”(computed)中可以看到每个元素计算后的样式。
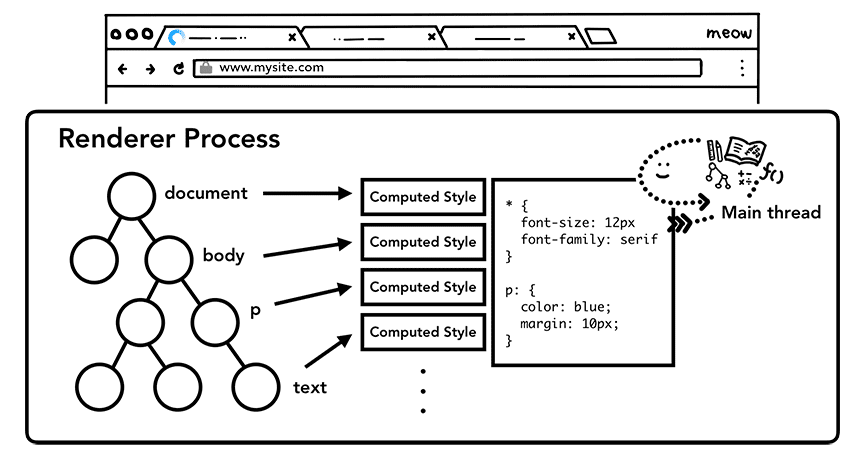 Figure 3: The main thread parsing CSS to add computed style(主线程解析 CSS 以应用样式)
Figure 3: The main thread parsing CSS to add computed style(主线程解析 CSS 以应用样式)
就算网页没有提供任何 CSS,每个 DOM 节点仍然会有计算的样式。这是因为浏览器有一个默认的样式表:点击查看 Chrome 的默认的样式源代码。
布局
到这一步,渲染器进程知道了文档的结构,也知道了每个节点的样式。但基于这些信息仍然不足以渲染页面。比如,你通过电话跟朋友说:“画一个红色的大圆形,还有一个蓝色的小方形”,你的朋友仍然不知道该画成什么样。
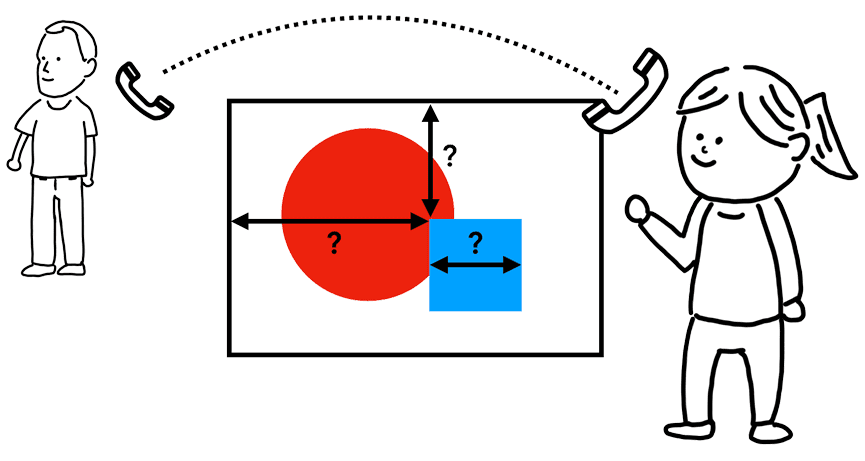 Figure 4: A person standing in front of a painting, phone line connected to the other person(一个人站在画板前面,电话线连接到另一个人)
Figure 4: A person standing in front of a painting, phone line connected to the other person(一个人站在画板前面,电话线连接到另一个人)
布局,就是要找到元素间的几何位置关系。主线程会遍历 DOM 元素及其计算样式,然后构造一棵布局树,这棵树的每个节点将带有坐标和大小信息。布局树与 DOM 树的结构类似,但只包含页面中可见元素的信息。如果元素被应用了 display: none,则布局树中不会包含它(visibility: hidden 元素会包含在内)。类似地,通过伪类 p::before{content: 'Hi!'} 添加的内容会包含在布局树中,但 DOM 树中却没有。
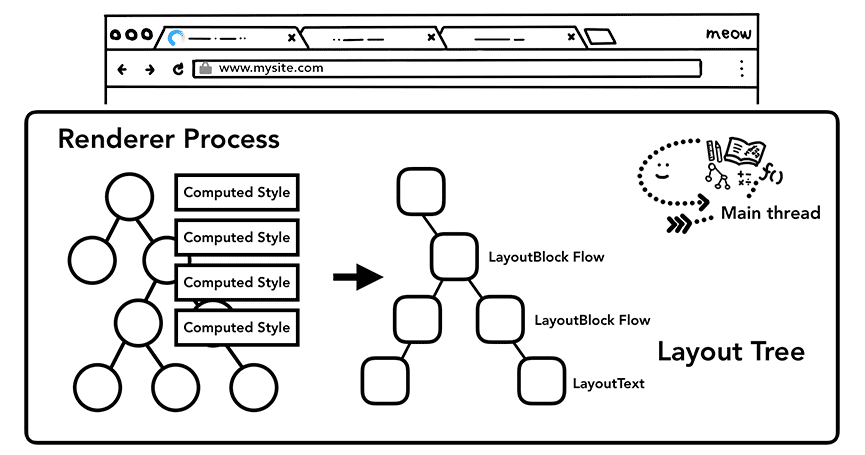 Figure 5: The main thread going over DOM tree with computed styles and producing layout tree(主线程根据样式遍历 DOM 树然后生成布局树)
Figure 5: The main thread going over DOM tree with computed styles and producing layout tree(主线程根据样式遍历 DOM 树然后生成布局树)

确定页面的布局并不简单,它要考虑很多很多因素。比如,字体大小、文本换行都会影响段落的形状,进而影响后续段落的布局。CSS 可让元素浮动到一边、隐藏溢出边界的内容、改变文本显示方向。可想而知,布局阶段的任务是非常艰巨的。谷歌有一个团队专门负责布局,感兴趣的话,可以看看他们在 YouTube 上的分享。
绘制
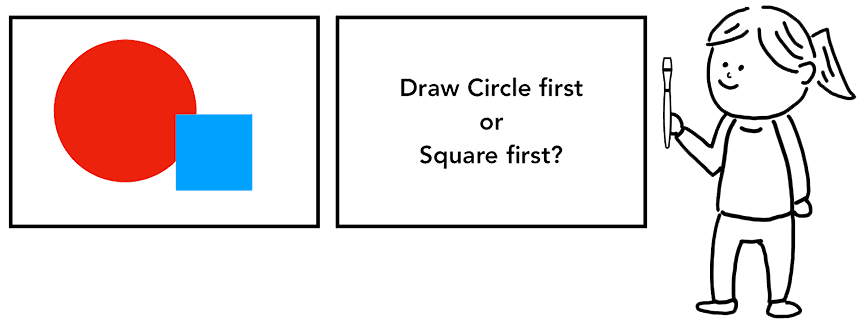 Figure 7: A person in front of a canvas holding paintbrush, wondering if they should draw a circle first or square first(一个人拿着画笔站在画板前面,想着是应该先画圆形还是先画方形)
Figure 7: A person in front of a canvas holding paintbrush, wondering if they should draw a circle first or square first(一个人拿着画笔站在画板前面,想着是应该先画圆形还是先画方形)
有了 DOM、样式和布局,仍然不足以渲染页面。还要解决先画什么后画什么,即绘制顺序的问题。比如,z-index 影响元素叠放,如果有这个属性,那么就不能简单地按元素在 HTML 中出现的顺序进行绘制。
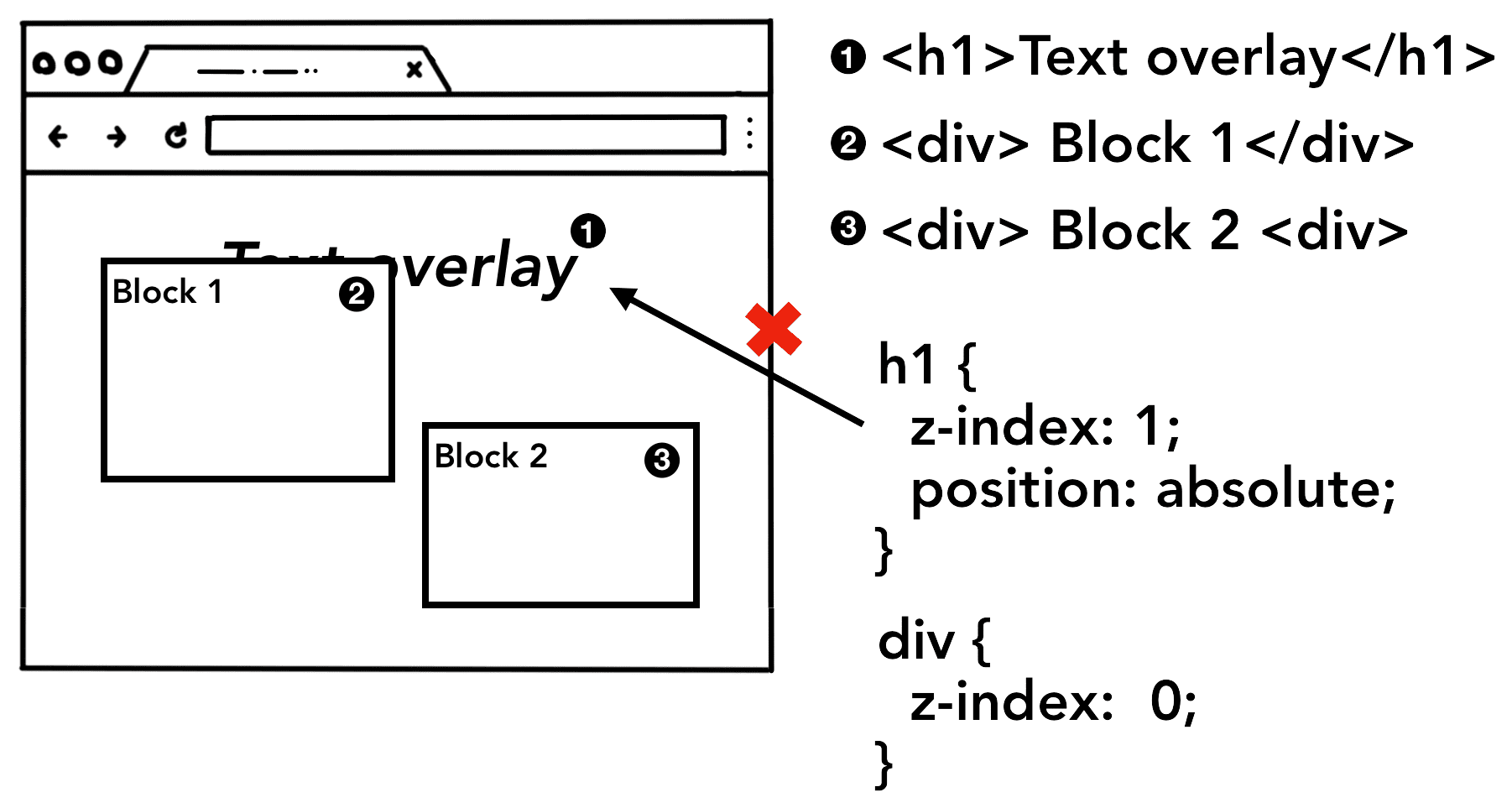 Figure 8: Page elements appearing in order of an HTML markup, resulting in wrong rendered image because z-index was not taken into account(页面上的元素只根据 HTML 代码的顺序进行显示,结果导致图片被遮挡了,因为没考虑到 z-index 属性)
Figure 8: Page elements appearing in order of an HTML markup, resulting in wrong rendered image because z-index was not taken into account(页面上的元素只根据 HTML 代码的顺序进行显示,结果导致图片被遮挡了,因为没考虑到 z-index 属性)
因此,在这一步,主线程会遍历布局树并创建绘制记录。绘制记录是对绘制过程的注解,比如“先画背景,然后画文本,最后画矩形”。如果你用过 <canvas>,应该更容易理解这一点。
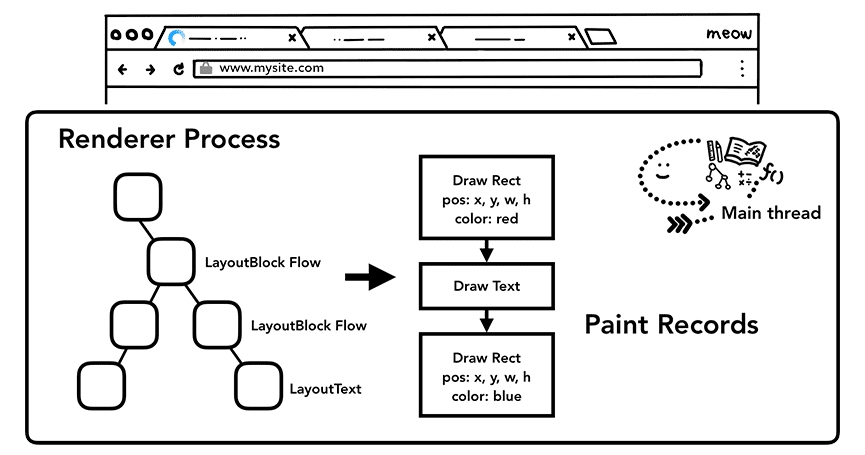 Figure 9: The main thread walking through layout tree and producing paint records(主线程遍历 布局树,并产出绘制记录)
Figure 9: The main thread walking through layout tree and producing paint records(主线程遍历 布局树,并产出绘制记录)
渲染是一个流水线作业(pipeline):前一道工序的输出就是下一道工序的输入。这意味着如果布局树有变化,则相应的绘制记录也要重新生成。

如果元素有动画,浏览器就需要每帧运行一次渲染流水线。目前显示器的刷新率为每秒 60 次(60fps),也就是说每秒更新60帧,动画会显得很流畅。如果中间缺了帧,那页面看起来就会“闪眼睛”。
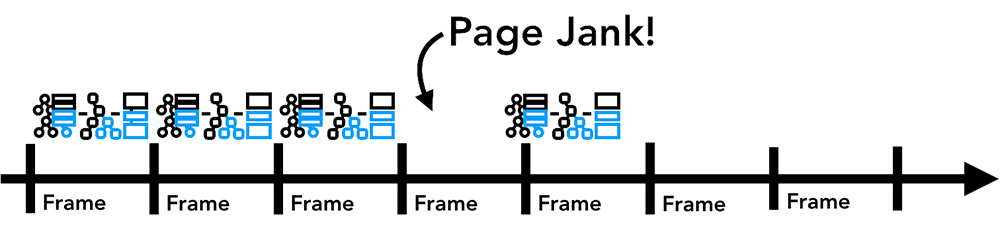 Figure 11: Animation frames on a timeline(时间轴上的动画帧)
Figure 11: Animation frames on a timeline(时间轴上的动画帧)
即便渲染操作的频率能跟上屏幕刷新率,但由于计算发生在主线程上,而主线程可能因为运行 JavaScript 被阻塞。此时动画会因为阻塞被卡住。
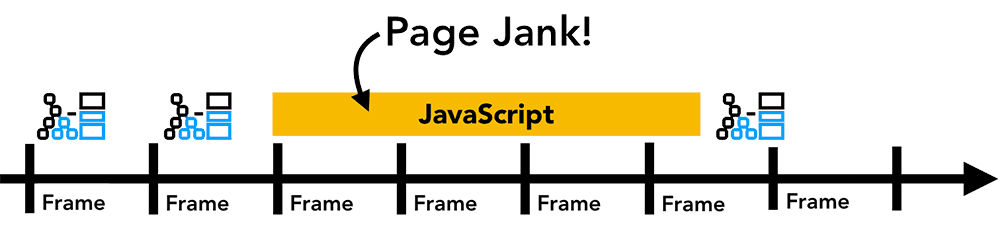 Figure 12: Animation frames on a timeline, but one frame is blocked by JavaScript(时间轴上的动画帧,但其中几个帧被 JS 阻塞了)
Figure 12: Animation frames on a timeline, but one frame is blocked by JavaScript(时间轴上的动画帧,但其中几个帧被 JS 阻塞了)
此时,可以使用 requestAnimationFrame() 将涉及动画的 JavaScript 操作分块并调度到每一帧的开始去运行。对于不必操作 DOM 的 JavaScript 耗时计算操作,可以考虑使用 Web Worker,从而避免阻塞主线程。
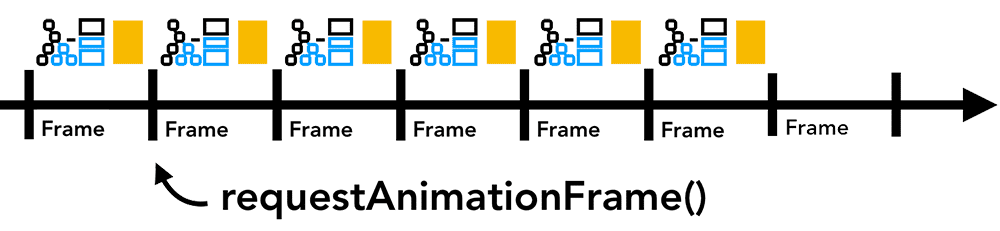 Figure 13: Smaller chunks of JavaScript running on a timeline with animation frame(在一条时间轴上,更小 JS 代码块和动画帧一起运行,动画帧不会被阻塞)
Figure 13: Smaller chunks of JavaScript running on a timeline with animation frame(在一条时间轴上,更小 JS 代码块和动画帧一起运行,动画帧不会被阻塞)
合成
知道了文档结构、每个元素的样式、页面的几何关系,以及绘制顺序,接下来就该绘制页面了。具体该怎么绘制呢?答案是栅格化。栅格化的过程,就是将刚刚提到的信息转换为屏幕上的像素。
最简单的方式,可能就是把页面在当前视口中的部分先转换为像素。然后随着用户滚动页面,再移动栅格化的画框(frame),填补缺失的部分。Chrome最早的版本就是这样干的。

但现代浏览器会使用一个更高级的步骤——合成(composite)。什么是合成?合成是将页面不同部分先分层并分别栅格化,然后再通过独立的合成器线程合成页面。这样当用户滚动页面时,因为层都已经栅格化,所以浏览器唯一要做的就是合成一个新的帧。而动画也可以用同样的方式实现:先移动层,再合成帧。
可以在 DevTools 中使用 Layers panel 查看该网站是如何划分为多个图层的

怎么分层?为了确定哪个元素应该在哪一层,主线程会遍历布局树并创建分层树(这一部分在开发工具的“性能”面板中叫“Update Layer Tree”)。如果你发现如果页面某些部分应该独立一层(例如滑入式侧边菜单),但该部分却没有成为一个独立分层,那你可以在 CSS 中给它加上 will-change 属性来显式提醒浏览器。
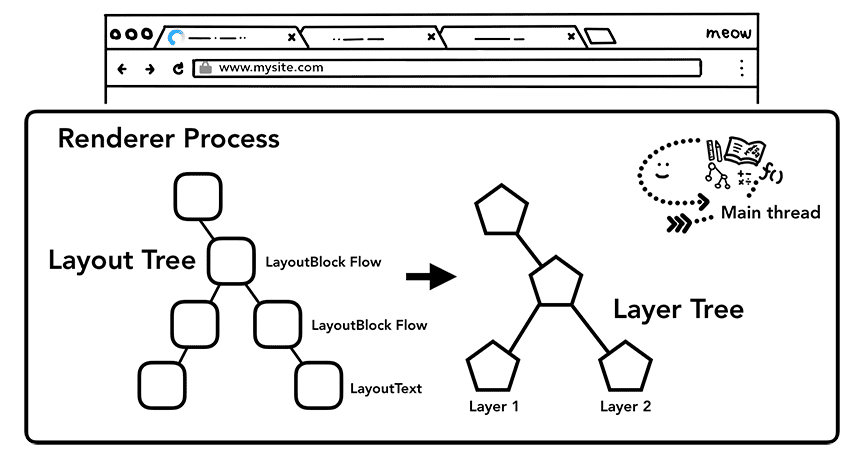 Figure 16: The main thread walking through layout tree producing layer tree(主线程遍历布局树以产出分层树)
Figure 16: The main thread walking through layout tree producing layer tree(主线程遍历布局树以产出分层树)
分层并不是越多越好,合成过多的层有可能还不如每帧都对页面中的一小部分执行一次栅格化更快。关于这里边的权衡,可以参考 Stick to Compositor。
创建了分层树,确定了绘制顺序,主线程就会把这些信息提交给合成器线程。合成器线程接下来负责将每一层转换为像素——栅格化。一层有可能跟页面一样大,此时合成器线程会将它切成小片(tile),再把每一片发给栅格化线程。栅格化线程将每一小片转换为像素后将它们保存在 GPU 的内存中。
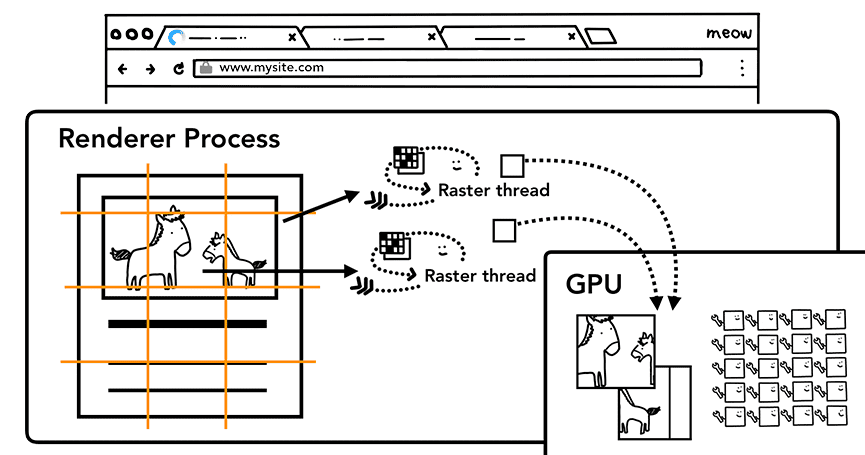 Figure 17: Raster threads creating the bitmap of tiles and sending to GPU(许多栅格化线程制作出一系列小片位图,然后发送给 GPU)
Figure 17: Raster threads creating the bitmap of tiles and sending to GPU(许多栅格化线程制作出一系列小片位图,然后发送给 GPU)
合成器线程会安排栅格化线程优先转换视口(及附近)的小片。而构成一层的小片也会转换为不同分辨率的版本,以便在用户缩放时使用。
所有小片都栅格化以后,合成器线程会收集叫做“绘制方块”(draw quad)的小片信息,以创建合成器帧。
- 绘制方块(Draw quads): 包含小片的内存地址、页面位置等合成页面相关的信息。(Contains information such as the tile’s location in memory and where in the page to draw the tile taking in consideration of the page compositing.)
- 合成器帧(Compositor frame): 由从多绘制方块拼成的页面中的一帧。(A collection of draw quads that represents a frame of a page.)
创建好的合成器帧会通过 IPC 提交给浏览器进程。与此同时,为更新浏览器界面,UI 线程可能还会添加另一个合成器帧;或者因为有扩展,其他渲染器进程也可能添加额外的合成器帧。所有这些合成器帧都会发送给 GPU,以便最终显示在屏幕上。如果发生滚动事件,合成器线程会再创建新的合成器帧并发送给 GPU。
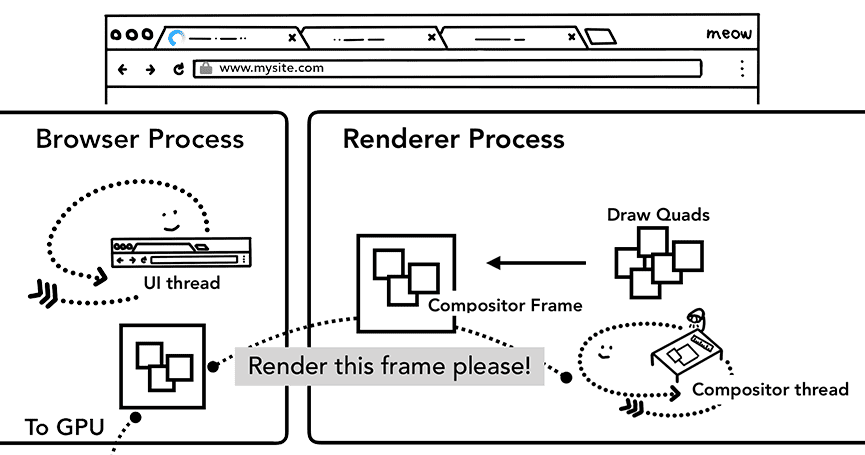 Figure 18: Compositor thread creating compositing frame. Frame is sent to the browser process then to GPU(合成器线程制作出合成帧,这些帧会被发送浏览器进程,然后送入 GPU)
Figure 18: Compositor thread creating compositing frame. Frame is sent to the browser process then to GPU(合成器线程制作出合成帧,这些帧会被发送浏览器进程,然后送入 GPU)
使用合成的好处是不用牵扯主线程。合成器线程不用等待样式计算或 JavaScript 执行。这也是为什么“只需合成的动画”被认为性能最佳的原因。因为如果布局和绘制需要再次计算,那还得用到主线程。
交互
最后,我们看一看合成器如何处理用户交互。说到用户交互,有人可能只会想到在文本框里打字或点击鼠标。实际上,从浏览器的角度看,交互意味着来自用户的任何输入:鼠标滚轮转动、触摸屏幕、鼠标悬停,这些都是交互。
当用户绘制手势(比如触摸屏幕)时,浏览器进程最先接收到该手势。但是,浏览器进程仅仅知道手势发生在哪里,因为标签页中的内容是渲染器进程处理。因此浏览器进程会把事件类型(如touchstart)及其坐标发送给渲染器进程。渲染器进程会处理这个事件,即根据事件目标来运行注册的监听程序。
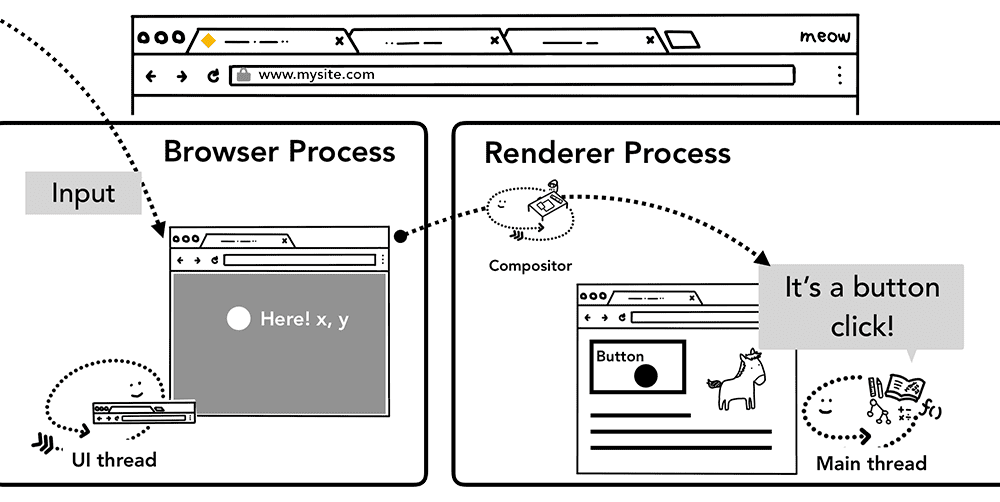 Figure 1: Input event routed through the browser process to the renderer process(输入事件通过浏览器进程发送到渲染器进程)
Figure 1: Input event routed through the browser process to the renderer process(输入事件通过浏览器进程发送到渲染器进程)
合成器接收输入事件
具体来说,输入事件是由渲染器进程中的合成器线程处理的。如前所述,如果页面上没有注册事件监听程序,那合成器线程可以完全独立于主线程生成新的合成器帧。但是如果页面上注册了事件监听程序呢?此时合成器线程怎么知道是否有事件要处理?这就涉及一个概念,叫“非快速滚动区”(non-fast scrollable region)。
非快速滚动区
我们知道,运行 JavaScript 是主线程的活儿。在页面合成后,合成器线程会给附加了事件处理程序的页面区域打上 “Non-Fast Scrollable Region” 的记号。有了这个记号,合成器线程就可以在该区域发生事件时把事件发送给主线程。
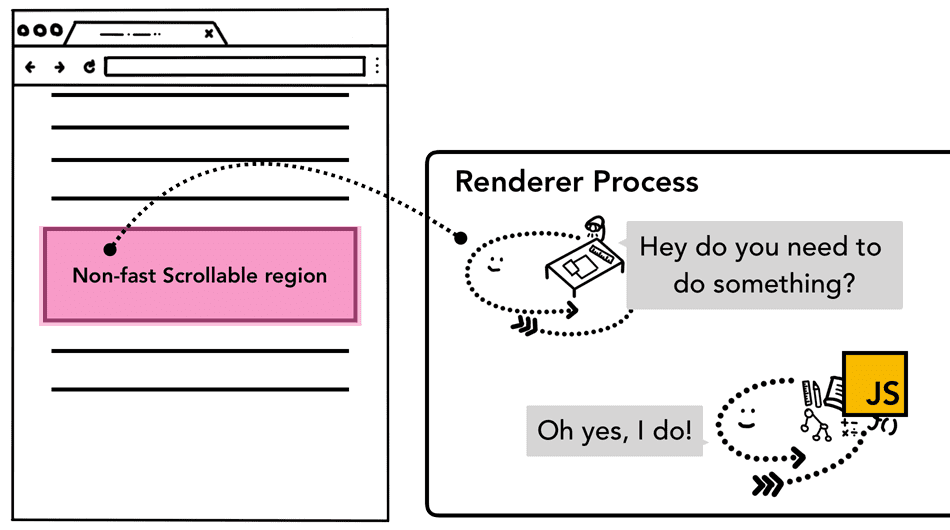 Figure 3: Diagram of described input to the non-fast scrollable region(在非快速可滚动区域上交互的示意图)
Figure 3: Diagram of described input to the non-fast scrollable region(在非快速可滚动区域上交互的示意图)
如果事件发生在这个区域外,那合成器线程会继续合成新帧而不会等待主线程。
提到注册事件,有一个常见的问题要注意。很多人喜欢使用事件委托来注册处理程序。这是利用事件冒泡原理,把事件注册到最外层元素上,然后再根据事件目标决定是否执行任务。
1
2
3
4
5
document.body.addEventListener('touchstart', evt => {
if (evt.target === area) {
evt.preventDefault()
}
})
上面代码的写法,可以让一个事件处理程序面向多个元素,因此,这种高效的写法很流行。然而,从浏览器的角度来看,这样会导致整个页面被标记为“非快速滚动区”。这也就意味着,即便事件发生在那些不需要处理的元素上,合成器线程也要每次都跟主线程沟通,并等待它的回应。于是,合成器线程平滑滚动的优点就被抵销了。
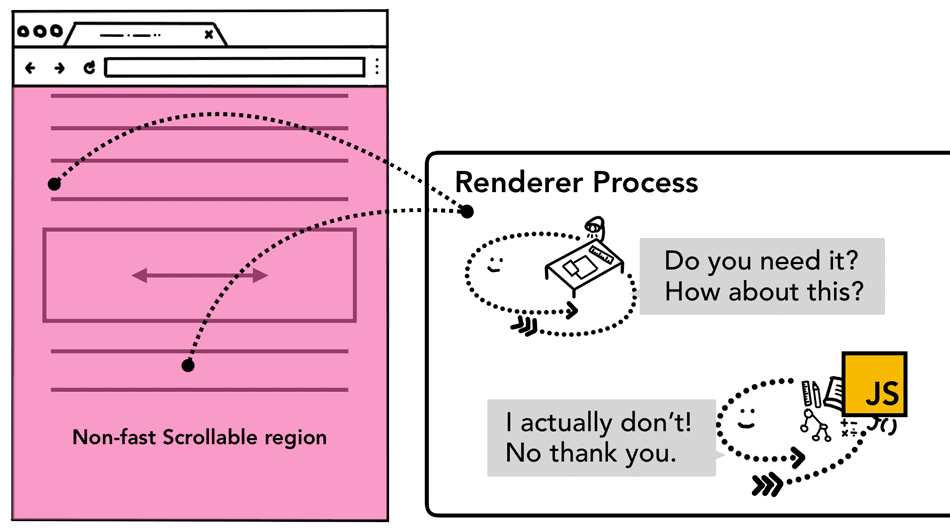 Figure 4: Diagram of described input to the non-fast scrollable region covering an entire page(与整个页面都是非快速可滚动区域交互的示意图)
Figure 4: Diagram of described input to the non-fast scrollable region covering an entire page(与整个页面都是非快速可滚动区域交互的示意图)
为避免使用事件委托带来的副作用,可以在注册事件时传入 passive: true。这个选项会提醒浏览器,你仍然希望主线程处理事件,但与此同时合成器线程也可以继续合成新的帧。
1
2
3
document.body.addEventListener('touchstart', evt => {
...
}, { passive: true })
检查事件是否可以取消
此外,检查事件是否可以取消也是一个优化策略。假设页面中有一个盒子,你想限制盒子中的内容只能水平滚动。
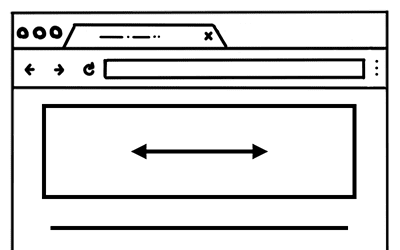 Figure 5: A web page with part of the page fixed to horizontal scroll(网页中有一部分固定为水平滚动的页面)
Figure 5: A web page with part of the page fixed to horizontal scroll(网页中有一部分固定为水平滚动的页面)
使用 passive: true 可以让页面平滑滚动,但为了限制滚动方向而调用 prevenDefault() 则不会避免垂直滚动。此时可以检查 evt.cancelable。
1
2
3
4
5
6
7
8
document.body.addEventListener('pointermove', evt => {
if (evt.cancelable) {
evt.preventDefault(); // 阻止原生滚动
/*
* 其他操作
*/
}
}, { passive: true })
当然,也可以使用 CSS 规则,如 touch-action,来完全取消事件处理程序。
1
2
3
#area {
touch-action: pan-x;
}
找到事件目标
合成器线程把事件发送给主线程以后,要做的第一件事就是通过命中测试(hit test)找到事件目标。命中测试就是根据渲染器进程生成的绘制记录数据和事件坐标找到下方的元素。
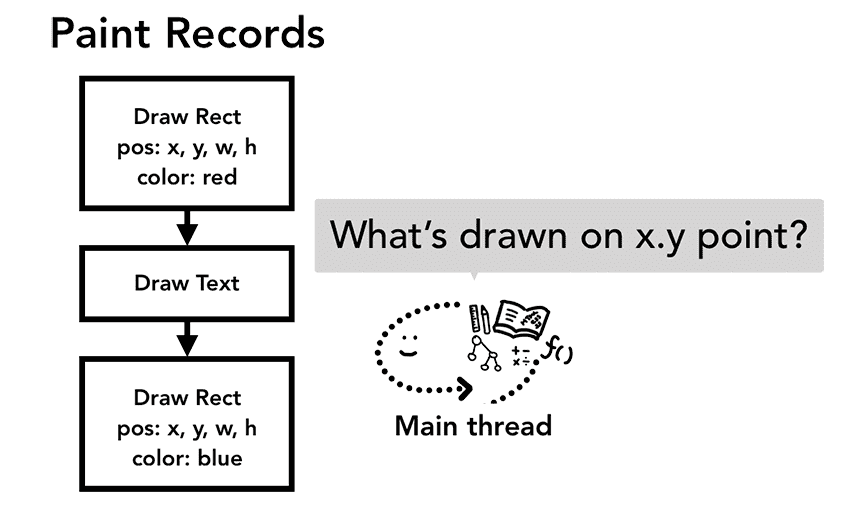 Figure 6: The main thread looking at the paint records asking what’s drawn on x.y point(主线程查看绘制记录,从而得知 x y 坐标上绘制了什么内容)
Figure 6: The main thread looking at the paint records asking what’s drawn on x.y point(主线程查看绘制记录,从而得知 x y 坐标上绘制了什么内容)
尽量减少对主线程的事件分派
另外,事件还有一个触发频率的问题。常见的触屏设备每秒会产生 60~120 次触碰事件,而鼠标每秒会产生约 100 次事件。换句话说,输入事件具有比每秒刷新60次的屏幕更高的保真度。
如果像 touchmove 这种连续事件,以每秒 120 次的频率发送到主线程,相比更慢的屏幕刷新率而言,就会导致过多的命中测试和 JavaScript 执行。
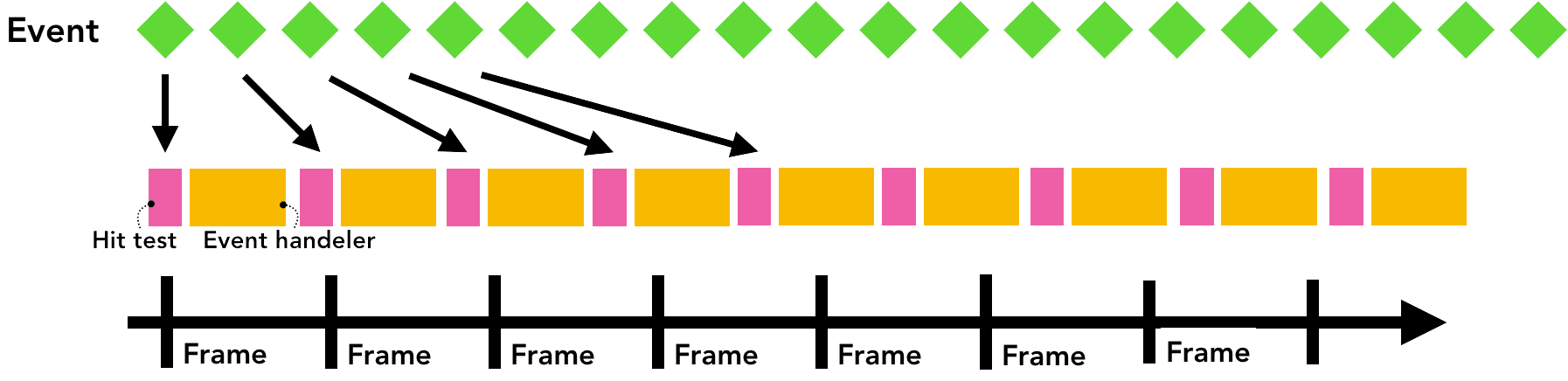 Figure 7: Events flooding the frame timeline causing page jank(时间线上充斥了许多事件帧,导致页面阻塞)
Figure 7: Events flooding the frame timeline causing page jank(时间线上充斥了许多事件帧,导致页面阻塞)
为把对主线程过多的调用降至最少,Chrome 会合并(coalesce)连续触发的事件(如 wheel、mousewheel、mousemove、pointermove、touchmove),并将它们延迟到恰好在下一次requestAnimationFrame 之前派发。
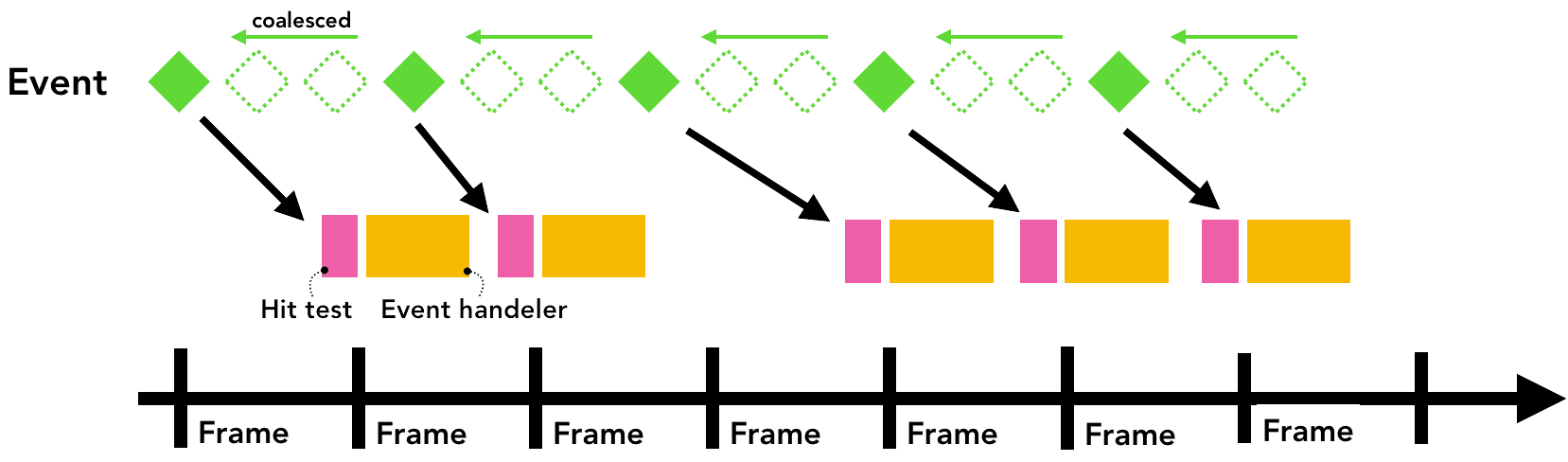 Figure 8: Same timeline as before but event being coalesced and delayed(和之前的时间线相同,但一些事件被合并和延迟了,从而不阻塞页面)
Figure 8: Same timeline as before but event being coalesced and delayed(和之前的时间线相同,但一些事件被合并和延迟了,从而不阻塞页面)
对于其他离散触发的事件,像 keydown、keyup、mouseup、mousedown、touchstart 和touchend 则会立即派发。
使用 getCoalescedEvents 获取帧内事件
合并后的事件在多数情况下足以保证不错的用户体验。但是,在一些特殊应用场景下,比如需要基于 touchmove 事件的坐标生成轨迹的绘图应用,合并事件就会导致丢失一些坐标,影响所绘线条的平滑度。
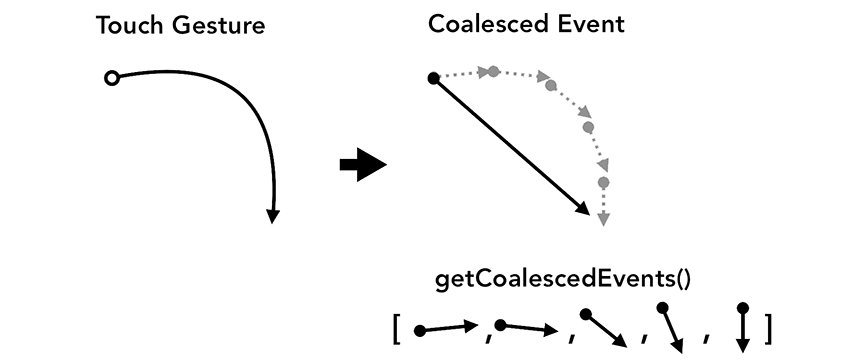 Figure 9: Smooth touch gesture path on the left, coalesced limited path on the right(左边是顺滑的触摸手势路径;右边是板直的合并路径)
Figure 9: Smooth touch gesture path on the left, coalesced limited path on the right(左边是顺滑的触摸手势路径;右边是板直的合并路径)
此时,可以使用指针事件的 getCoalescedEvents 方法,取得被合并事件的信息:
1
2
3
4
5
6
7
8
window.addEventListener('pointermove', event => {
const events = event.getCoalescedEvents()
for (let event of events) {
const x = event.pageX
const y = event.pageY
// 使用 x 和 y 坐标绘制线条
}
})
收尾
这是个小小的结尾。相信不少前端开发者早已知道给 <script> 标签添加 defer 、async 属性的作用。通过阅读本文,你应该也知道了为什么在注册事件监听器时最好传入 passive: true 选项,知道了 CSS 的will-change 属性会让浏览器做出不同的决策。事实上,不止上面这些,看完看懂篇文章,你甚至也会对其他关于浏览器性能优化的细节感到豁然开朗,从而对更多关于网页性能的话题会产生兴起。而这正是深入理解现代浏览器的重要意义和价值所在,因为它为我们打开了一扇大门。
英语原文链接:
- inside browser part1 - 2018.09
- inside browser part2 - 2018.09
- inside browser part3 - 2018.09
- inside browser part4 - 2018.09
再次感谢原文作者:Mariko Kosaka
[完]